Data-driven testing (DDT) is an approach to test design where the test data (input and output values) is separated from the actual test case. The test data can be stored in one or more central data sources and shared/reused across different test cases. By storing your test data in a central repository (local storage, Excel spreadsheet, XML file, or SQL database), you can run the same test with a new set of data each time, avoiding redundant design and execution of repetitive tests cases. Toward the end of the test cycle, you can store test data to provide a clear audit trail of what was and wasn’t covered by a test.
Test cases are commonly designed using variables in test steps. Variable placeholders call and retrieve values from a data source instead of using hard-coded or fixed values. Each time you execute the test case, the variable is replaced with the test data in the corresponding data source. With this approach, a new test case simply requires a new row of test data in the data source. Additionally, this approach provides a clear separation of testing logic from the actual test data, which reduces maintenance efforts (that is, any changes to test steps do not affect the test data and vice-versa).
In a nutshell, DDT can be visualised as follows:

When designing test cases using the DDT approach, the focus should be on mapping the test data and the different combinations and variations (negative and positive) to properly meet the business requirements and ensure adequate test coverage. By doing so, when executing test cases using Zephyr Scale, the variable placeholders in test steps are replaced by the values available in the test-data table, ensuring complete reusability of the test steps.
DDT can be used with manual test scenarios, enabling manual test scripts to run together alongside their respective data sets. In DDT, the following operations are performed in a loop for each row of test data in the data source:
Test data is retrieved
Test data is input into the system under test (SUT) and simulates other actions
Expected values are verified
Test execution continues with the next set of test data
Working with Test Data
Create a test case and enable the test data functionality in the Test Script tab.
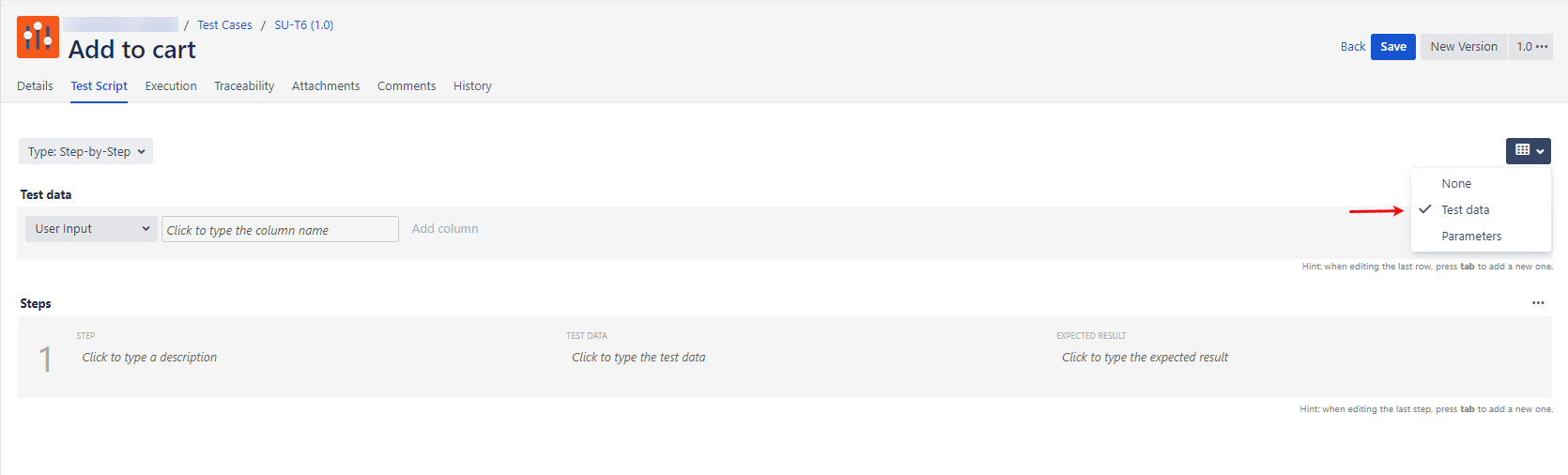
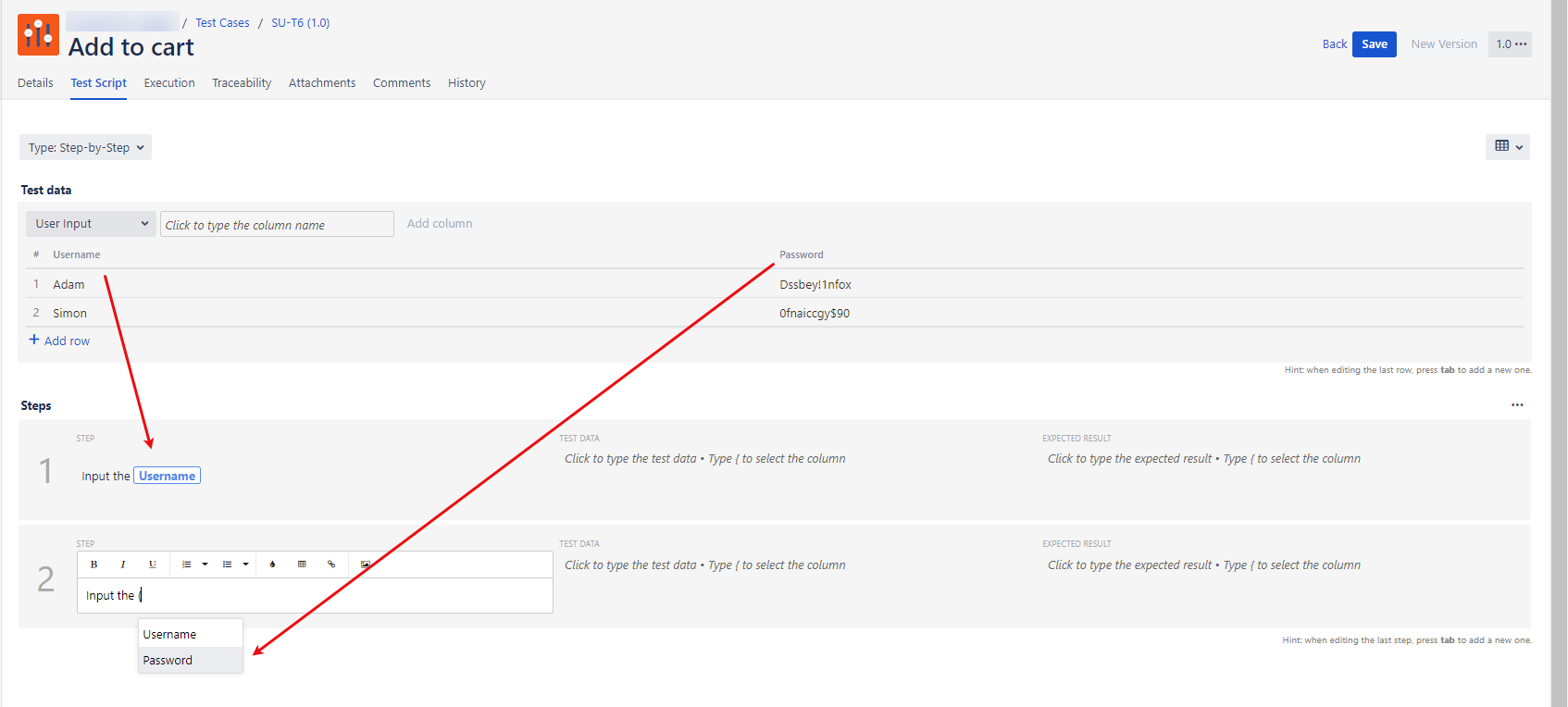
Add columns (variables) to the test-data table. In the steps, you can reference a column (variable) by typing a { brace (curly bracket), which triggers a drop-down list with column options. When the test case is ready to be executed in the Test Player, the test steps are repeated to ensure complete coverage.
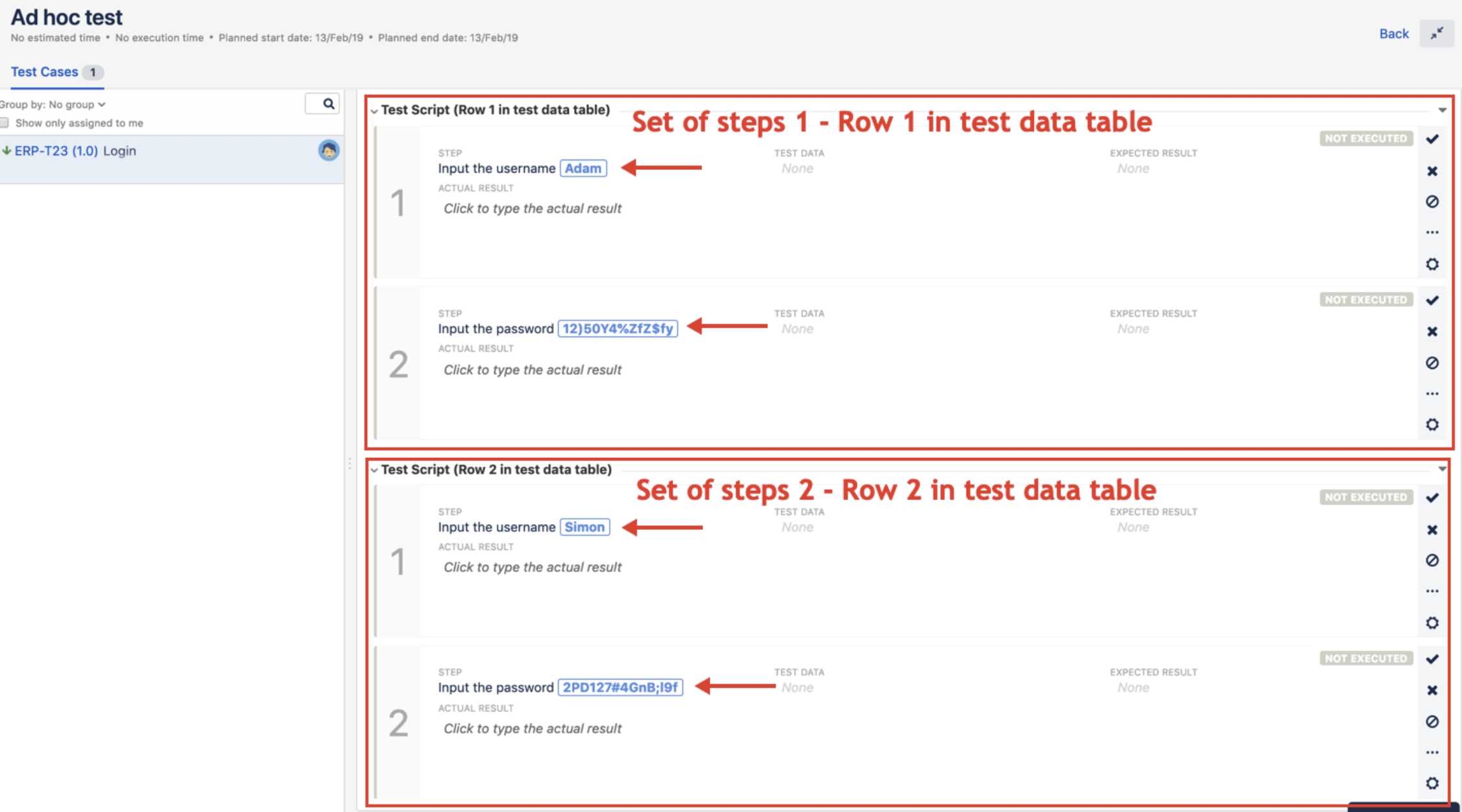
In the Test Player screen, you'll notice all steps are unfolded in a flat step list. Also, each step will be unfolded during the test execution with the parameter replaced with the values passed by the main test case. Bear in mind, each row in the test data table will create a new group of steps during the unfolding procedure as shown in the image below.
Working with Data Sets
Data sets are basically reusable sets of test data. If you plan to use the same test data between test cases, this is the right option for you.
To use data sets:
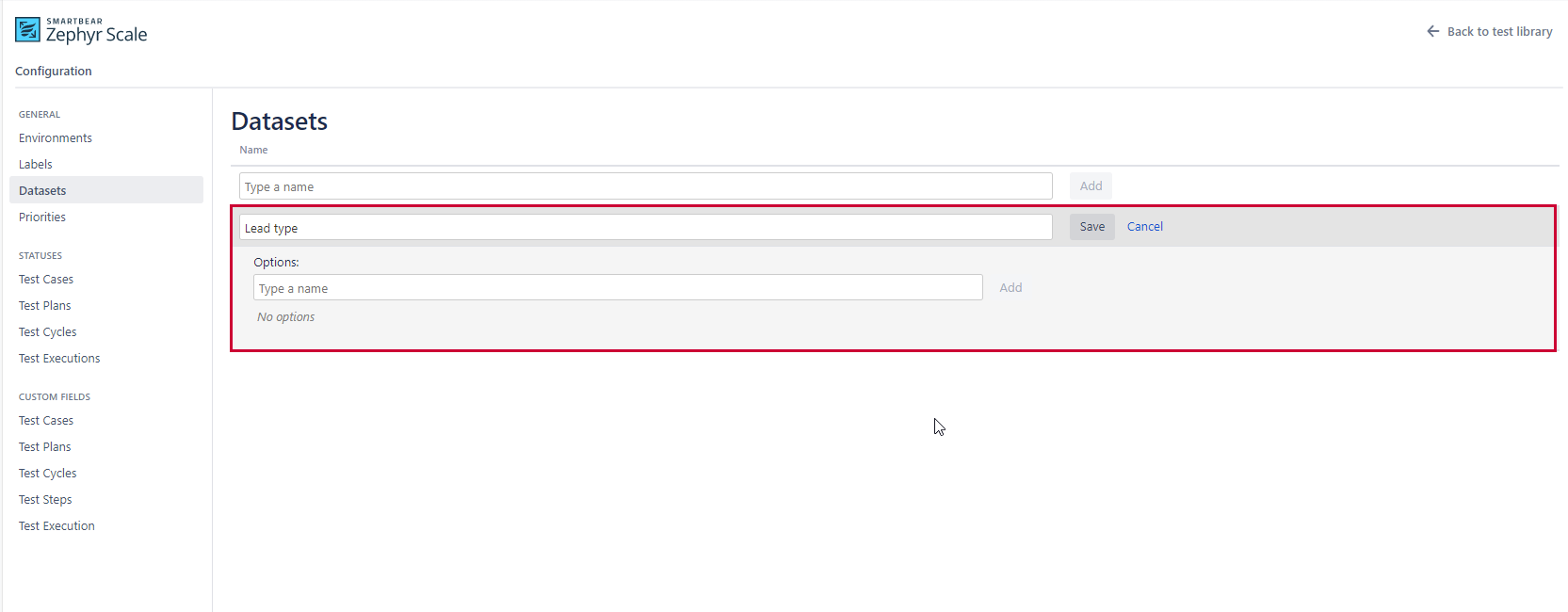
Create a data set in the configurations section of Zephyr Scale and add some options
Select the Test Data option for your test case
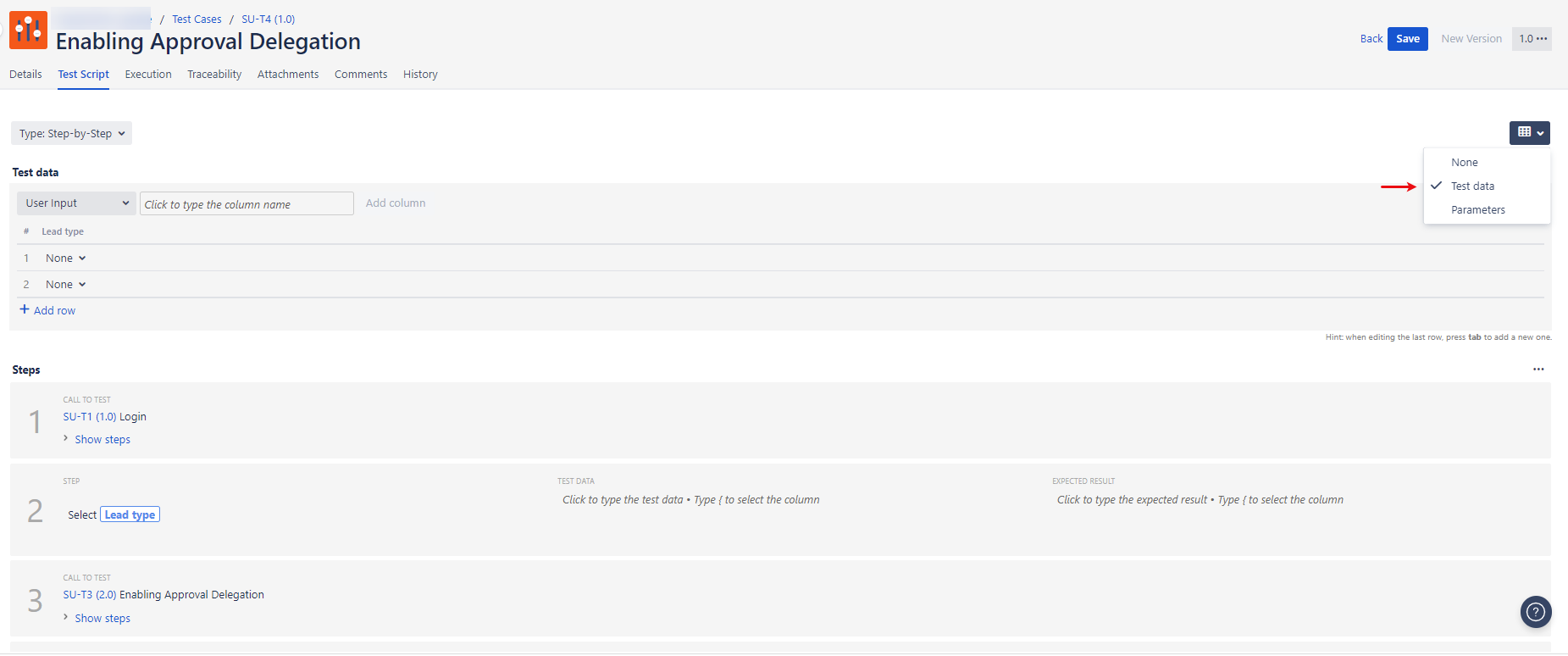
Select the data set you want to use in your test case

Add the data set as a column

Set the options that you want to use in your test case
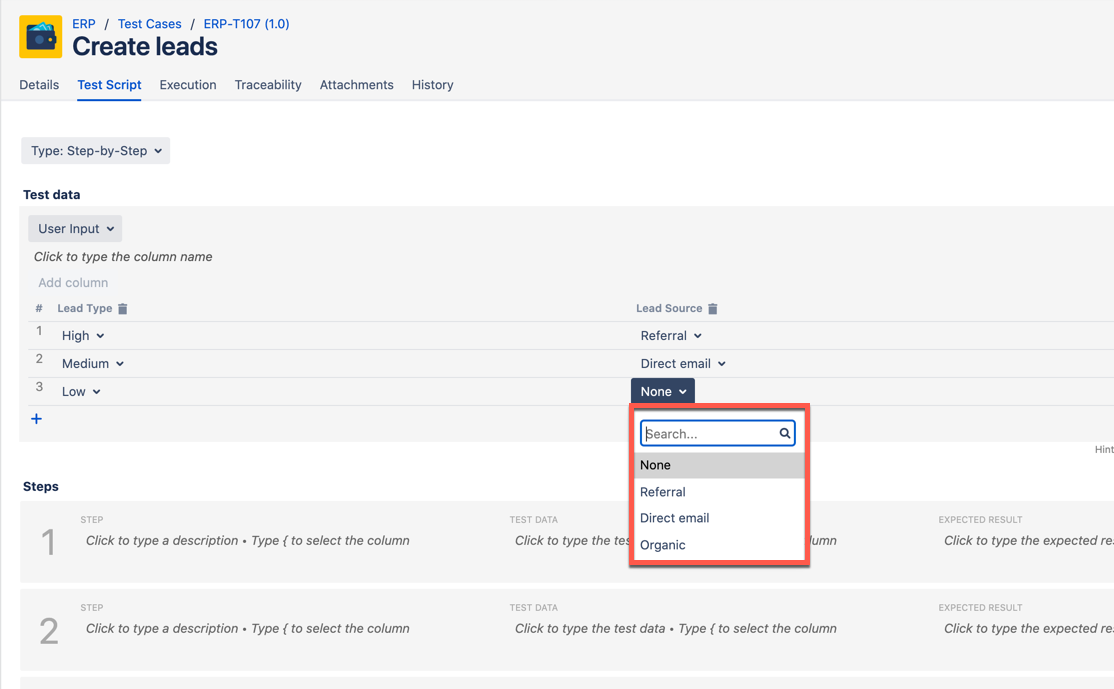
Reference the test data column in the test case steps
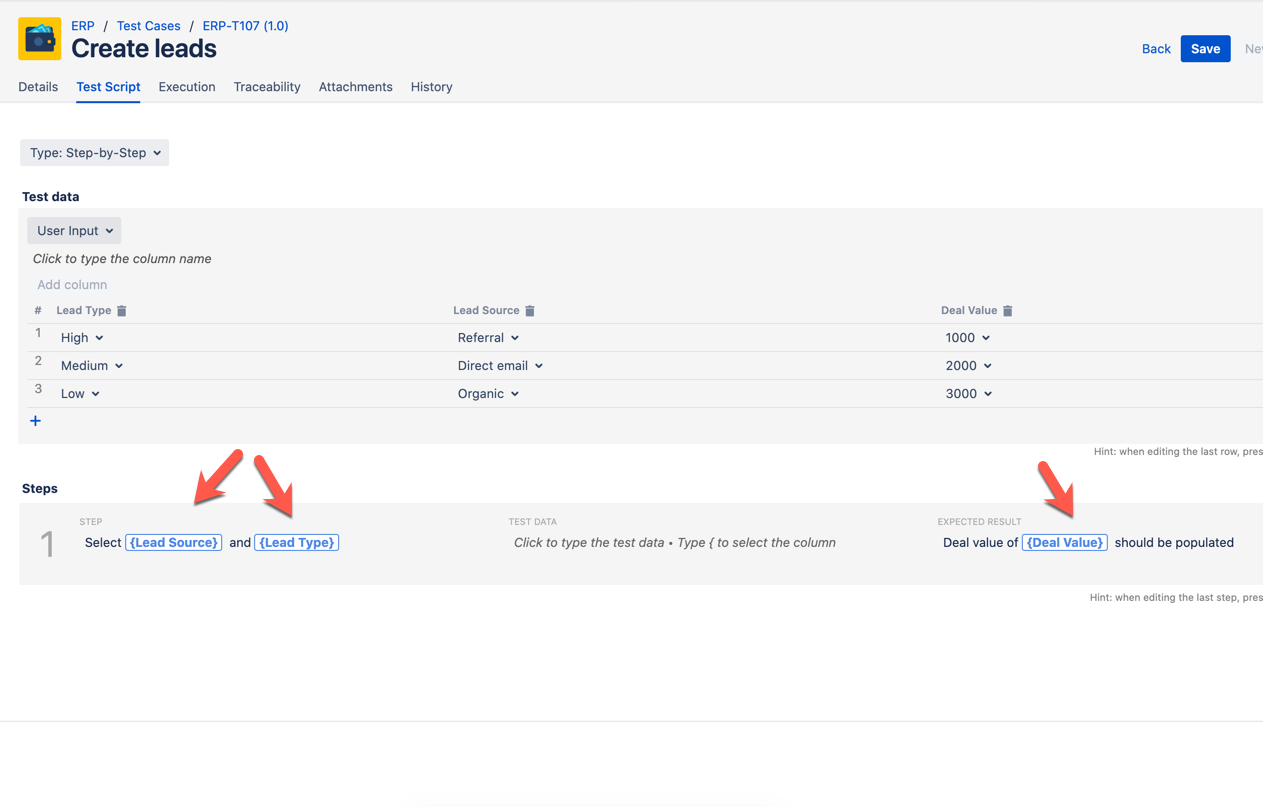
Save the test case
When you view the test case in the Test Player, you'll see that there is a new row of steps for each variation/row in the table.