
Regular expressions are coded strings that define an infinite number of possible matches. You can use regular expressions to specify:
- The sought-for text in the Find dialog.
- Masks for the failure emulation's parameters.
This topic consists of the following sections:
 Regular Expression Tokens
Regular Expression Tokens| Note: | In this topic certain text fragments are marked with color. The following convention is used:
Regular expression pattern is highlighted with purple color. Literal text to which the regular expression is applied is highlighted with olive color. Literal text that matches the regular expression is highlighted with teal color. |
Regular Expression Tokens
The syntax of regular expression patterns that can be used in various AQTime areas is slightly different due to the differences in regular expression engines used. For a list of tokens that are handled by various AQTime features, follow the links below:
Tokens Understood by Find Dialog
The following table lists regular expression tokens that are recognized by the Find dialog. For more information about tokens recognized by the Failure Emulator profiler, see the table below.
| Token | Description | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| ^ | Beginning of a line. For instance, the ^a search pattern lets you find all lines that start with a. | ||||||||
| $ | End of a line. For instance, the a$ search pattern lets you find all lines that end with a. | ||||||||
| . | The period means any single character except the newline. For instance, a.c matches abc, adc, aec but not aaac or abbc. To search for any symbol (including the newline symbol), use the [\s\S] pattern or enable the “single-line mode” with the (?s) modifier. | ||||||||
| * | The asterisk is a symbol-“repeater”. * means 0 or more occurrences of the preceding character. For instance, the abc*d pattern matches abd, abcd, abccd, but not a or abcx. The .* pattern matches a string of any length (including the empty string) that does not contain the newline symbol. The * token is equivalent to {0,}. | ||||||||
| + | The plus is a symbol-“repeater”. + indicates 1 or more occurrences of the preceding character. For instance, the ab+d pattern matches abbd or abbbd, but does not match abcd or abbcd. The + token is equivalent to {1,}. | ||||||||
| ? | The question mark means 0 or one occurrence of the preceding character. For example, abc?d will find abd and abcd, but not abccd. The ? token is an equivalent to {0,1}. | ||||||||
| { } | The { } token has the following meanings:
|
||||||||
| [ ] | Any single character specified in brackets. For instance, d[ab]e matches dae or dbe and does not match dwe or dxe. To include the ] character into the search, make it either first, or last character in the range or use \]. For example, []abc], [abc]] or [ab\]cd]. | ||||||||
| [^ ] | Any single character except those that are specified in brackets. For instance, d[^bc]e matches dae or dxe, but not dbe or dce. d[^b-d]e matches dae, but not dbe, dce or dde. | ||||||||
| [a-b] | Any single character from a to b, inclusive. For instance d[k-x]e matches dke, dme and dxe, but not dze. To include the - character into the search, make it either first, or last character in the range or use \-. For example, [-ab], [abc-] or [a\-z]. | ||||||||
| [^a-b] | Any single character not in the range a through b. For instance a[^k-x]z matches abz, aiz and ayz, but not akz. | ||||||||
| a|b | Either a or b. For instance, ab|cde matches ab and cde, but not abde. The ht(m|ml) pattern will find htm and html, but not htl. | ||||||||
| \ | Backslash is used to specify that special characters, such as ^, $ or . (dot),
do not belong to the search pattern and should be treated literally.
For instance, the \$10 pattern lets you find the $10 string. To search for a backslash, use the double backslash pattern (\\).
Some more examples:
d[a\-c]e will find dae, d-e or dce, but not dbe. d[\^bc]e will find d^e, dbe or dce. |
||||||||
| \xNN | A symbol whose hexadecimal ASCII code is NN. For example, A\x31B will
find the string A1B. (Hexadecimal 31 is ASCII
code of 1).
You can also use \x{NNNN} to search for characters whose code occupies more than one byte (Unicode). |
||||||||
| \t | Tab character. | ||||||||
| \n | Newline character. | ||||||||
| \r | Carriage return character. | ||||||||
| \f | Form feed character. | ||||||||
| \w | “Word” character: an alphanumeric symbol or underscore (_). This token is equivalent to [A-Za-z0-9_]. | ||||||||
| \W | Any symbol except for “word” characters. This token is equivalent to [^A-Za-z0-9_]. | ||||||||
| \d | Any digit character. This token is equivalent to [0-9]. | ||||||||
| \D | Any character except for digit. This token is equivalent to [^0-9]. | ||||||||
| \s | “Whitespace” character: a space, tab (\t), newline (\n), carriage return (\r) and form feed (\f). This token is equivalent to [ \t\n\r\f]. | ||||||||
| \S | Any symbol except for “whitespace” characters. This token is equivalent to [^ \t\n\r\f]. | ||||||||
| \b | Indicates a word boundary, that is, a position between a word character and a whitespace character. For example, oo\b matches oo in foo, but not in foot. Similarly, \bfo matches fo in foot, but not in afoot. | ||||||||
| \B | Indicates any position in a word except for boundary. For example, oo\B matches oo in foot, but not in foo. | ||||||||
|
Note: |
You can use the \t, \w, \W, \d, \D, \s, \S, \b and \B expressions within brackets. For example, b[\d-e]b will find b1b, b2b or beb. |
Tokens Understood by Failure Emulator Profiler
AQTime lets you emulate different application failures to verify application behavior in unexpected situations. For this purpose, AQTime includes the Failure Emulator profiler. It tracks whether the code of the profiled application contains lines that prevent the application from the emulated failure. For more information on the profiler, see Failure Emulator Profiler - Overview.
When you add the desired failure emulation to the project (using the Add New Failure Emulation wizard), you need to specify parameters for this emulation. For example, you may need to enter the name of the file, the name of the registry key or something else. To specify such parameters, AQTime allows using regular expressions. To add a regular expression to the parameter value, you can either enter it manually or select it from the list (when you select an item from the list, an appropriate character is added to the parameter value right after the current cursor position):
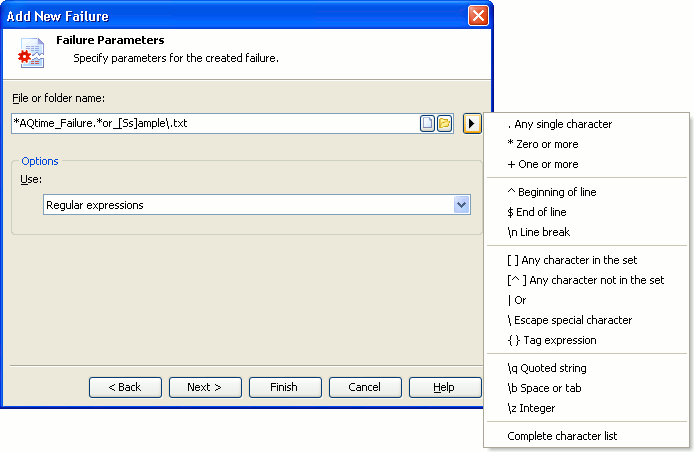
This list appears when you click the Regular Expression Builder button ( ) to the right of the specified parameter. Note that this list contains only commonly used tokens, for the complete list of available tokens, see the table below:
) to the right of the specified parameter. Note that this list contains only commonly used tokens, for the complete list of available tokens, see the table below:
| . | Matches any single character. For example, a.c matches abc,adc, aec but not aaac or abbc. |
| [] | Matches any single character specified in brackets. For instance, d[ab]e matches dae or dbe and does not match dwe or dxe. To include the ] character into the search, make it either first, or last character in the range or use \]. |
| ^ | If this token is specified at the beginning of the string enclosed in brackets, it matches any single character except for those inside the brackets. For instance, [^abc] matches d, x but not a, b or c.
If this token is specified at the beginning of the regular expression, it matches the beginning of the input string. For instance, [^abc] matches only those inputs that begins with "a", "b" or "c" character. |
| - | Indicates the range of characters within the brackets. For instance, [0-9] only matches the digits (characters from "0" to "9"). |
| ? | Indicates that the preceding character or group is optional, that is, it should either match once or not to match at all. For example, abc?d will find abd and abcd, but not abccd.
Note that this token is “greedy”, that is, it matches the longest possible string. For example, when searching on the string abc, ab? matches ab rather than a. |
| + | Indicates that the preceding character or group matches 1 or more times. For instance, the ab+d pattern matches abbd or abbbd, but does not match abcd or abbcd.
Note that this token is “greedy”, that is, it matches the longest possible string. For example, when searching on the string abbbb, ab+ matches abbbb rather than ab or abb. |
| * | Indicates that the preceding character or group matches 0 or more times.
Note that this token is “greedy”, that is, it matches the longest possible string. For example, when searching on the string abbbb, ab* matches abbbb rather than aab. |
| ??, +?, *? | Non-greedy versions of ?, +, and * tokens. These match as little as possible, unlike the greedy versions that match as much as possible (for example, given the input <abc><def>, <.*?> matches <abc> while <.*> matches <abc><def>). |
| () | Groups characters. For example, (ab)+ matches ab and abab but not acb.
To specify a round bracket that should be treated literally, precede it with a backslash: \( or \). |
| {} | Indicates a match group. You can use braces in regular expressions that retrieve values that match the expression in the braces. If you create the following regular expression: [0-9]+-[0-9]+, it will match 125-125, but not 125-abcd. However, you can use braces to reduce the size of a regular expression. For example, you may need to modify the expression above to make it find strings containing only similar numbers that are hyphenated. For this purpose, you can specify the first part as a group and then address the value that matches this part by a zero-based index of the match group. This is the index that is specified after the backslash, \n. For example, you can change the regular expression mentioned above in the following way {[0-9]+}-\0. This means that AQTime will replace the \0 expression with the string returned by the first match group. It will match 168-168, but not 125-168.
To specify a brace that should be treated literally, precede it with a backslash: \{ or \}. |
| \ | A backslash indicates that the next character token (such as ?, !, *, - and others) should be treated literally. For example, \$10 matches the string $10. To match a backslash itself, use the double backslash pattern (\\).
When followed by a number (for example, \0), indicates the match group at the specified index (from 0). Important: In JScript, C++Script and C#Script, you should use double backslashes to interpret the subsequent special character literally: \\?, \\., \\2 and so on. To match a backslash character, use the \\\\ pattern. |
| $ | Matches the end of a line. For instance, the a$ search pattern lets you find all lines that end with a. |
| a|b | Matches either the a or b character or a group. For example, A|abc matches Abc and abc, but not A. The htm|(ml) pattern matches htm and html, but not htl or ml. |
| ! | Matches a not followed by b. For example, colo!ur matches color, but not colour. |
| \a | Matches any alphanumeric character. This token is equivalent to [A-Za-z0-9]. |
| \b | Matches a whitespace character. |
| \c | Matches any alphabetic character. This token is equivalent to [A-Za-z]. |
| \d | Matches any decimal digit. This token is equivalent to [0-9]. |
| \h | Matches any hexadecimal digit. This token is equivalent to [0-9A-Fa-f]. |
| \n | Matches a new line character. |
| \q | Matches a quoted string. This token is equivalent to ("[^"]*")|('[^']*'). |
| \w | Matches a word. This token is equivalent to [a-zA-Z]+ or \c+. |
| \z | Matches an integer number. This token is equivalent to [0-9]+ or \d+. |
To learn more about regular expressions, please see www.regular-expressions.info
Modifiers
Modifiers specify how the engine interprets regular expressions. They toggle the search engine’s behavior modes. The following modifiers are available:
You can specify the modifier in the expression using the (?key) or (?-key) syntax (where key stands for the modifier key and minus sign specifies the disabled state for the corresponding modifier). If you try to specify unsupported modifier keys an error occurs. The modifiers can be applied to the whole expression or only to a sub-expression. For example:
| (?i)Las Vegas | matches Las vegas and Las Vegas |
| (?i)Las (?-i)Vegas | matches Las Vegas but not Las vegas |
| (?i)(Las )?Vegas | matches Las vegas and las vegas |
| ((?i)Las )?Vegas | matches las Vegas, but not las vegas |