
When using optical character recognition in your tests, you may face the following issues:
 N blocks were found …
N blocks were found …N blocks were found …
If your tested UI element contains several instances of the sought-for text, by default, TestComplete will get the first instance it will find by searching from left to right and from top to bottom. To resolve the issue, you can do the following:
Set search preferences
In keyword tests
Configure your OCR Action operation to select the needed text fragment among all other found fragments. To do this, set the Preferences parameter of the operation:

In scripts
Use the SelectionPreference parameter of the OCR.Recognize.BlockByText method to specify how the method should select the needed text fragments among all found fragments. For example:
JavaScript, JScript
Python
VBScript
DelphiScript
C++Script, C#Script
This way, you can get the following text fragment among all found text fragments:
- Topmost
- Bottommost
- Leftmost
- Rightmost
- Largest
- Smallest
- Nearest to the center
Narrow down the search area
For example, specify the UI element that contains only the needed text.
As an alternative, if you recognize text in an image, narrow down the search scope by specifying a rectangular within the image. For example:
JavaScript, JScript
Python
VBScript
DelphiScript
C++Script, C#Script
Notes:
-
Using images as a search area is not applicable for the OCR Action operation in keyword tests.
-
In scripts, if you use an image as a search area, you will not be able to simulate user actions on the found text fragment. You only will be able to get the text and boundaries of the fragment.
Adjust your search pattern string
Use the search pattern string that identifies the target text fragment uniquely. You can use the asterisk ( * ) or question mark ( ? ) wildcards to specify the text to search. The asterisk corresponds to a string of any length (including an empty string), the question mark corresponds to any single character (including none).
Implement a custom search algorithm
-
Iterate through all recognize text blocks.
-
Check the properties of each block (for example, its text or boundaries) until you find the text block you need.
In keyword tests
To iterate through text blocks, you can use the For Loop or While Loop operations. To check the block properties, you can use the If Then operation. To get the total number of recognized text blocks, use the OCR.Recognize.BlockCount property. To get an individual text block, use the OCR.Recognize.Block property.
In scripts
To iterate through recognize text blocks, you can use the Loop statement provided by your scripting language. To get the total number of recognized text blocks, use the OCR.Recognize.BlockCount property. To get an individual text block by its index, use the OCR.Recognize.Block property.
TestComplete fails to connect to the recognition service
To recognize text contents, TestComplete uses the ocr.api.dev.smartbear.com web service by SmartBear. If the computer, on which you run your tests, cannot access the web service, your test will report an error and will not be able to recognize any text.
To resolve the issue, make sure that your computer can access the service. If you have proxies or firewalls running in your network, make sure that they allow connecting to the server. Also, make sure that your firewall allows traffic through port 443. See Optical Character Recognition - Requirements.
Recognition results differ or recognition fails
Optical character recognition cannot ensure 100% accuracy. It depends on various factors like the recognition algorithms used, your screen resolution, the font style, the color and size your tested application uses to render text, the color of the background on which the text is rendered, the language of your text, and so on.
Recognition algorithms
TestComplete’s OCR engine is powered by the Google Vision API, and the results the engine returns depend on the values it receives from the API servers. These values can change from one test run to another as Google constantly improves their recognition algorithms. For example:
-
The engine might insert spaces into recognized phrases; strings like
Unit1orTestCompletecan be recognized asUnit 1orTest Complete. -
In some cases, the algorithms can recognize graphical elements or window borders as text. For instance, the word
Unitnear a vertical line can be recognized asIUnit.
Possible workarounds:
-
Insert wildcard characters (
*or?) into problematic strings. For example:Instead of … Use … Unit1Unit*1, or*Unit*1TestCompleteTest*Complete -
Create test commands for iterating through recognized text blocks. See Check Text Contents and Get Text Blocks.
-
Try using technologies alternative to OCR.
Visual factors
Recognition results depend on the screen resolution and image details. Recognition may fail if –
-
The size of the text you are trying to recognize is too small:
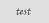
-
The text is rendered on a complex background (for example, on a gradient background) or on a background with intersecting lines:


-
The image, in which you are trying to recognize text, contains artifacts or noise. For example:
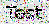
To work around the problem, you can try doing the following:
-
Narrow down the search area: search for the text in a window region rather than in the entire window. See the example above.
-
Try using technologies alternative to OCR.
See Also
Optical Character Recognition
Possible Alternatives to Optical Character Recognition