
In LoadComplete, you use regular expressions to find data in requests and server responses in user scenarios.
Requests and responses can contain a large amount of complex data, and it may be difficult to specify a regular expression that will match the data you need exactly. In this case, you can use subexpressions to specify the needed data.
For example, a server response contains a field whose value you want to extract. A regular expression may not specify the field value precisely. In this case, you can define a regular expression that matches a larger data segment in the response and then use a subexpression to find the value you need.
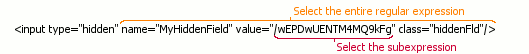
To point the piece of data for a subexpression to match, you use parentheses in the regular expressions. In other words, parentheses are placeholders for subexpressions in the entire regular expression string:
-
For data selectors and data replacers you create in corresponding panels in the Scenario editor, you specify the subexpression in the Attributes column:

Click the image to enlarge it.
-
For correlation rules you define in the Data Correlation Options dialog, you specify subexpressions in the Attributes text box or include them into expressions that define the data to be extracted or replaced (see below):

Click the image to enlarge it.
You specify the needed subexpression in the $number format, where number is the subexpression position. $1 corresponds to the first subexpression; $2 - to the second one, and so on. $0 indicates data returned by the entire regular expression.
| Note: | LoadComplete allows specifying up to 9 sub-expressions inside a regular expression. |
If the regular expression should include the parentheses symbols literally, use a backslash ( \ ) before parentheses:
Using Subexpressions in Data Correlation Rules
Data correlation rules in LoadComplete search for dynamic parameters in requests and responses.
You can use subexpressions in correlation rules to –
-
Specify the name of the variable that LoadComplete will use to store the value of the correlated dynamic parameter.

Click the image to enlarge it.
A subexpression in the Variable Name text box will get the needed piece of data that the regular expression specified in the Find names and extra attributes | Expression text box matches.
-
Specify the part of the regular expression that LoadComplete will use to search for the data to be extracted:

Click the image to enlarge it.
A subexpression in the Select from responses | Expression text box will get the needed piece of data that the regular expression specified in the Find names and extract attributes | Expression text box matches.
-
Specify the part of the regular expression or the path that LoadComplete will use to search for the data to be replaced:

Click the image to enlarge it.
A subexpression in the Replace in requests | Expression text box will get the needed piece of data that the regular expression specified in the Select from responses | Expression text box matches.
-
Specify the piece of data LoadComplete will extract from responses or that LoadComplete will replace in requests:

Click the image to enlarge it.
A subexpression in the Attributes column will get the needed piece of data that the regular expression specified in the Select from responses | Expression or Replace in requests | Expression text box matches.
See Also
Regular Expressions Syntax
About Data Selectors
About Data Replacers
Data Correlation