
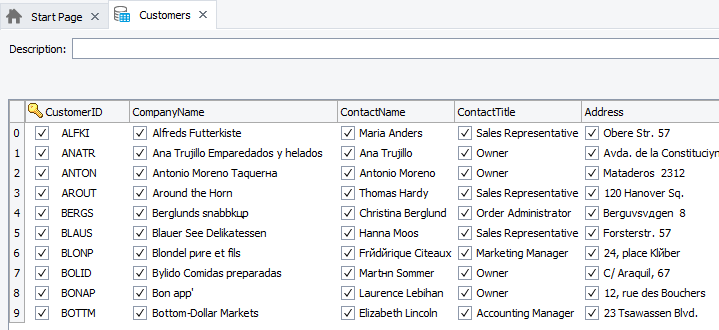
A key column (or a combination of columns) is used to uniquely identify rows in table and database table elements during comparison. For this purpose, the key values must be different in each row. Usually, the key columns hold some unique identifiers, such as the employee IDs or SSNs. In the image below, the column that holds the customer IDs is chosen as the key:
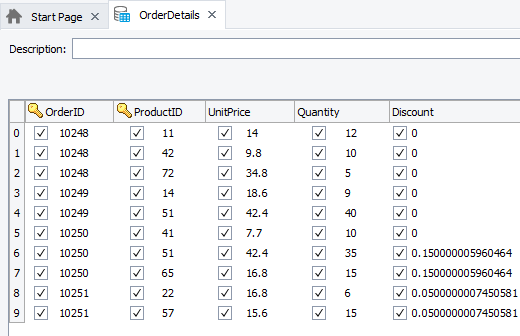
If columns in the tabular control or the database do not have unique values, it is possible to choose two or more key columns. Values within one column may be duplicated, but the combination of values from all columns must still be different in each row. For instance, in the following image, the “Order ID” column does not provide a unique identification, because it contains duplicate values. However, the combination of values in the “Order ID” and “Product” columns is different in each row, so these two columns were chosen as the keys:
The absence of key columns in the retrieved recordset effects how TestComplete compares the table or database table element’s data with the data of the underlying recordset (see How Comparison Works). Key columns can be useful if the records’ order in the tested control or database are different from test to test. For example, if the control data is sorted, TestComplete will still be able to match records in the table element and the control, because it will identify the records by key values rather than by their visual order.
Below are some notes on choosing keys for table and database table checkpoints:
- For efficiency purposes, it is recommended that the key columns contain numeric values or short strings.
- Avoid using names as keys, because names are not unique.
- For database table elements, the selected key field may not necessarily be marked as a key field in the underlying database.
- Since key fields are used to identify database records, the database provider, which is used to access data, should support the sorting of records in these fields. In other words, if you mark a field as a key, the provider should be able to sort data in this field. The sorting is typically supported for ordinary data types: string, integer, float, date, time and boolean. Some database engines may also support sorting on fields of other types. However, the list of supported fields differ from one provider to another. To prevent problems, it is recommended to select the Key check box for the fields of ordinary types and avoid selecting the check box for non-ordinary fields such as hyperlink or memo.
- Do not modify key values in the table or database table elements. Since key values are used to uniquely identify records, changes in key values can cause TestComplete to not be able to match records in the table or database table element with records in the underlying recordset.
 How the Database Comparison Procedure Works
How the Database Comparison Procedure Works